Learning>Rawgraphs 1.0
How to make an alluvial diagram (RAWGraphs 1.0)
4 min.alluvial diagramsankey
In this guide you’ll learn how to create an alluvial diagram to see socio-demographic information about people on the Titanic. Before starting we will define a small vocabulary to avoid misinterpretations. We will call ‘nodes’ the black rectangles. We will call ‘flows’ the coloured areas linking nodes. We will call ‘steps’ the vertical groups of nodes.
Alluvial diagrams are in many ways similar to sankey diagrams: they represents weighted flows among nodes. Alluvial diagrams are a specific kind of Sankey diagrams: they use the same logic to show how the same set of items regroups according to different dimensions.
Before starting we can define a small vocabulary, to avoid misinterpretations. We will call ‘nodes’ the black rectangles. We will call ‘flows’ the colored areas linking nodes. We will call ‘steps’ the vertical groups of nodes.
In RAWGraphs, you don’t define directly the size of edges among nodes. In our application each line of the dataset become a series of flows, each columns defines a step. The size of edges and of flows is therefore linked to the number of lines in the dataset containing the same couple of nodes. Flows coming from and going to the same couple of nodes are grouped.
GOAL OF THE TUTORIAL: Compare socio-demographic information about the passengers of the Titanic, trying to identify patterns among genre, age, fare class and chance to survive to the accident.
01. Paste your data
The first step is to copy and paste your data into RAWGraphs.
The data must be structured in this way: each line of the dataset is an item, and each column is a property of such item.
To make an example:
| Name | Age | City |
| John | 30 | London |
| Richard | 20 | Berlin |
| Frank | 20 | Berlin |
| Gabriele | 30 | Milan |
The data must contain at least two columns defining properties. Each additional column will define a new step in the alluvial diagram. An additional optional column can be used to define the line weight.
Here you can see the dataset we are going to use:
You can also select it directly in the app through clicking on ‘Try our samples’ > ‘Titanic’s Passengers’. In few second you should see the green bar saying “1309 records in your data have been successfully parsed!”.
02. Choose the layout
After pasting your data, scroll down and select the “Alluvial Diagram” chart layout.

03. Map your dimensions
The alluvial diagram has two visual variables.
| VARIABLE | TYPE | REQUIRED | MULTIPLE | DESCRIPTION |
| Steps | String, numbers | [fa class=”fa-asterisk”] | [fa class=”fa-tags”] | It accept multiple values, at least two column must be selected. Each dragged column will define a step (a vertical group of nodes). The dragging order is also the visualization order. For each unique value found in each column a node will be created. |
| Size | Numbers | Defines the weight of each line of the dataset. If not defined, all the lines will have the same weight. |
It’s time to map your data and create the visualization. On the left you have the list of dimensions in your dataset, on the right the available visual variable of the bar chart layout.
Drag and drop the dimensions as following:

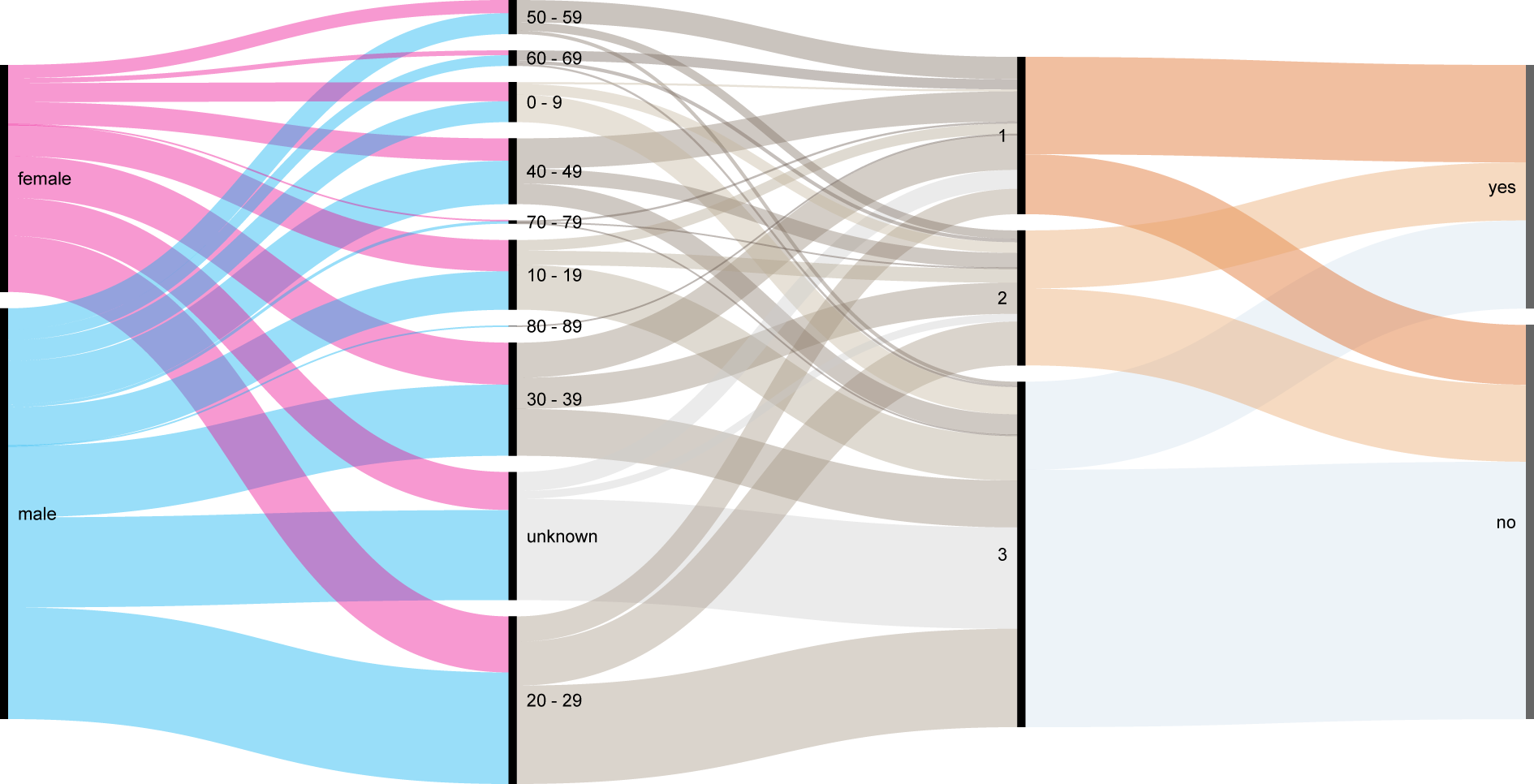
In this way we will create four different Steps. The first is Gender, with two nodes, male and female. The size of the two nodes is proportional to the number of nodes containing that value.
The second step is Age group, and it’s composed by 9 nodes: the first 8 for each decade, and a last one for all the people with unknown age. Also in this case the size of each node is proportional to the number of rows containing that specific value. The flows among nodes in the two steps represent the number of lines in the dataset sharing the same couple of values: for example the largest flow is from the node ‘male’ in the Gender step and the ‘20-29’ node in the Age groups step.
The same logic rules the following steps. The third one is Class and contains three nodes (first, second, third), the last step is Survival, containing two nodes (yes for survived, no for not survived).
We won’t use the size dimension in this tutorial.
04. Options
To reach the final results we can customize the visualization with some parameters you can find next to the visualization.
For the alluvial diagram the options available are the following:
| OPTION | DESCRIPTION |
| width | artboard width in pixels |
| height | artboard height in pixels |
| Nodes width | Width of black bars representing nodes, in pixels. |
| Sort by | Sorting of nodes inside each step. It can be ‘automatic’ (trying to reduce the number of overlappings among flows), ‘size’ (nodes ordered from the biggest to the smallest), and ‘alphabetical’. |
| Color scale | The color of flows. The color is defined by the source node. For each unique value found in the dimension dragged as ‘steps’ a color is defined. |
For the final results we have set the options as following:
- Width to 945
- Height to 483
- Set the colors as following. Copy and paste the hex codes as following:
- “1” to #DD5F12, “2” to #E8A264, “3” to #D3E1EE;
- “0 – 9” to #c2b49a, “10 – 19” to #b0a28b, “20 – 29” to #a2937f, “30 – 39” to #948573, “40 – 49” to #877768, “50 – 59” to #7b6b5d, “60 – 69” to #6f5f54, “70 – 79” to #64544a, “80 – 89” to #594a41, “unknown” to #cccccc;
- “female” to #ec008b, “male” to #00adef.
Here is the finished chart. You can export it in svg or png using the download function at the bottom of the page.

How to cite this guide
"How to make an alluvial diagram (RAWGraphs 1.0)", by RAWGraphs Team. Licensed under CC BY-NC-SA 4.0. Accessed: November 08, 2021, from undefined
Copy to clipboard
RAW
A project by

